
AutoPoC - Validating the Lack of Validation in PoCs
HoneyPoC was a project to look at how popular CVE PoCs could be. AutoPoC took that concept and enabled the mass creation of disinformation. Also, Data is beautiful.


A quick caveat before diving into the entire post, I have not dived into all of the data as there was so much, I might well do a follow-up post to this with more granular information. However, at a mere 6k words I hope you enjoy this post. The post is split into two sections to appease the different audiences that will likely read it. The first section acts as an overview with a quick summary of what the project does/did and a quickfire view of some of the interesting data then the second part will be a full deep dive into the different sections.

This blog post is an accompaniment to a talk I delivered at BSides London in 2021:
https://www.youtube.com/watch?v=zc-QM7mKAmg
The header image is a photo I took from 100 meters in the sky above the Campsie Hills in Scotland.
For those who may not be aware, around a year and a half ago I created a fake proof of concept for SIGRED aka CVE-2020-1350 which quickly built traction as it was a very much hyped up vulnerability within Windows. The proof of concept(PoC) was designed to execute a rickroll and send an HTTP/DNS request to a CanaryToken to harvest information about who ran the payload and on what system etc.
TL;DR Summary
As this post is rather large and contains a lot of nitty-gritty data, having spoken to a few folks it was suggested that a too long didn't read section be added to allow for a quick summary of what the project is, what the data is and what the outcome was.
HoneyPoC and AutoPoC are two combined projects that were created to investigate how easy it is to poison different feeds of data and whether there is integrity in parsing data and passing it to different parties. The secondary objective was to identify what range of people run things directly from GitHub, the preliminary findings from the original HoneyPoC project were that folks will run anything blindly it appeared but as I automated the project more it became apparent that different geographic locations had a deeper interest in different types of CVEs and software vulnerabilities.
Summary of Findings
There were several key observations from the data enriched and analysed, the breakdown of executions falls into the following categories:
- Security Researchers - Curious as to what was being released there was a large number of executions from repeat IPs and ranges which indicated some security companies and users doing analysis of PoCs.
- Sandboxes - Similar to above there were a large number of executions that originated from sandboxes, likely submitted by researchers and defensive teams alike. A large amount of input was identified from sandboxes on the initial publication of the CVEs, a lot of it was assumed automatic indexing of GitHub followed by automatic submission to VirusTotal.
- Opportunistic Hackers/Bug Bounty Hunters - The largest amount of downloads and runs of the PoCs were from folks targeting (assumed) vulnerable systems. While the proofs of concept were benign, those downloading were under the impression they would return fruitful results. The PoCs captured the target host and as a result, I was able to map a lot of information to various bug bounty programs and companies' domains.
- Threat Intelligence Analysts - Due to the nature of what was posted, a large amount of the links, binaries and data ended up in various public and private threat intelligence feeds and as a result, were executed by various analysts, some were on purpose but a lot were accidental due to either lack of technical knowledge or lack of protection measures put into place to prevent fingerprinting legitimate machines.
- Threat Actors from specific geographic locations - There was a large amount of interest from China, Korea, Russia, US and Japan-based users, in addition when analysing the data there was a large amount of
.cnand.jpdomains targeted that were of interest. Reverse DNS revealed a lot of information on the target IP addresses mapped to the regions above. - Insider Threat/Internal Security Teams - When looking into the data I found several internal hostnames of several large companies, some came forward and informed me that they were indeed insider threats and thus the HoneyPoC caught the first stages of a breach in three cases! In another case, the company invited me to submit to their bug bounty as it was technically passive remote code execution as the binary had profiled the environment was running in based on the base domain; for example
acme.local. Upon discussion with their team it indicated that the PoC was being used by an internal security team for analysis.
Summary of Data
Here are a few snippets from my talk slide deck and an insight into some of the key data observed during the project.

- Total POCS Generated - 5263
- Total Amount of Github Accounts - 8
- Total Unique Executions - 19461
- Most Common OS Targetted - Windows
- Most Common Country Source - United States
- Most Common Targetted Destination - China (From the data it was usually China targeting other Chinese companies)
Summary Conclusion
The project started out as a bit of fun but grew into a long term data exploration project and identified a few fun holes along the way. The findings and overall data output shows that regardless of what is put out there, people will still run things without checking what they are or worse push them to threat intel feeds without checking what a proof of concept does or if it is even valid.
If you are a consumer of threat intel and you found your provider listed in this post, time to look around at what intelligence said provider is providing and if it really is of true value.
The bottom line of the entire post is validation is key to success and leveraging actionable intelligence is not only about technical validation but also about the validation of sources in general.
The Nitty-Gritty Full Fledged Details
The original repository contained four canary tokens, one in the PoC.exe binary, one in the CVE-2020-1350.exe binary, one in the README.PDF and one in the repository README.md.

If you want to read more and see the data from that initial experiment see the blog post below:
 Andy Gill
Andy Gill
The original proof of concept was for SIGRED (CVE-2020-1350), however following that I released two more through my GitHub, once burned twice shy:
- https://github.com/ZephrFish/CVE-2020-1350 - Original HoneyPoC
- https://github.com/ZephrFish/ExchangeRCE-CVE-2021-28480 - Second PoC released for Exchange CVE
- https://github.com/ZephrFish/CVE-2021-22893 - Third HoneyPoC released for PulseSecure VPN exploit
They are all still pretty highly ranked when you search for the CVE followed by an exploit and alas none of them were legitimate exploit code. They are all part of an accidental research project that has grown a lot since I initially trolled the internet with CVE-2020-1350 HoneyPoC.
Since writing this blog post I have renamed the projects to clearly label them as HoneyPoC so hopefully, folks won't run them but alas folks will run anything without reading sadly.
Case and point I released a project on GitHub a few months ago and tweeted about it:
Now if I tell people not to run an EXE how many still will? https://t.co/ZESda24YY7
— Andy Gill 🏴 (@ZephrFish) September 1, 2021
54 unique IPs cloned the repo down and a further 40 executions from non-sandbox IPs. I did however get some interesting output from some researchers who reversed the binary and sent additional headers for testing which was cool. Granted the executions were likely folks who follow me on Github and Twitter messing around but still interesting metrics.
 ZephrFish
ZephrFish
Why?
Originally the HoneyPoC was created as a bit of a joke and a semi-social experiment. However it quickly grew into a long term research project and upon releasing three HoneyPoC GitHub repositories via the manual process of repo creation and upload, I had a discussion with a few folks and I decided to automate both distribution and collection of results to see what the output would look like at scale when lots of CVE PoCs with legitimate-looking descriptions started to appear on GitHub.
It was originally a combination of Kevin Beaumont and others that suggested I try this based on this tweet (and yes I got a lot of initial hate because folks love to hate in this industry).
I legit think we should write a tool to automate generating honeytoken PoCs, by pulling CVE data and populating the scripts.. and then upload to GitHub regularly and see who uses them.
— Kevin Beaumont (@GossiTheDog) April 29, 2021
I think if we did every CVE for three months the results would be shocking.
I built out some infrastructure and started automating the code for the creation of proofs of concepts. I automated creation in a variety of steps but started out prototyping the proof of concept and how I wanted to template it. Initially, it started as a raw git repo with some binaries uploaded. However as I learned more about the ares library I built out the templates to suit and built more legit repos with instructions, descriptions and info around the CVE.
AutoPoC - Automated Chaos and Distributed Disinformation as a Service (DDaaS)

Taking all of the information gathered from the first, second and third HoneyPoC repositories combined with the idea of automating it. I set out to create a framework for the automated creation of proofs of concepts based on every CVE released in a period of time. The AutoPoC framework went through several iterations before I settled on the perfect formula for the creation and with help from a few folks, the code was streamlined and deployed.
The sole reason for building this at this stage was to see how easy it would be to create a distributed disinformation campaign at scale and via an anonymous GitHub or set of accounts that would not be directly attributed to me thus have more believability(because I'm not the boy who cried Proof of Concept). A feat I will not get over for a while, which instils distrust in binaries and PoCs released from now on from me which I am cool with.
How Does it Work?
The AutoPoC project itself is built from templates and automated polling via the ares library, the process for PoC creation works as follows:
- Stage 1: Poll CVEs from the Ares library which references https://cve.circl.lu/ to pull CVE IDs and then drop them into a list to iterate through and create canary tokens and instances for each CVE pulled.
- Stage 2a: Create Git Repo and Push updates to Repo from templated files, creation from supplied environmental variables. In its final form, the script pulls various environmental variables from a
.credfile like below:
{
"CVE_SEARCH":"BASEWORDSEARCH",
"CANARY_AUTH_TOKEN" : "APIKEY",
"CANARY_API_URL" : "https://UNIQUEID.canary.tools/api/v1/canarytoken/create",
"GITHUB_USERNAME" : "ACCOUNTNAME",
"GITHUB_TOKEN" : "TOKEN",
"PASTE_API_KEY" : "TOKEN",
"EMAIL_TO" : "RECIPIENT",
"EMAIL_PASSWORD" : "PWD",
"EMAIL_SERVER" : "MAIL SERVER IP",
"EMAIL_SERVER_PORT" : "MAIL PORT"
}- Stage 2b: Email User(me in this case) alert that new repo has been created, document the Repo Link, Pastebin link, CVEID and CanaryToken ID. Each template has variables to pre-fill and email content can be customised easily within the script.
- Stage 2c: Create Pastebin Entry with git repo name and CVE information - Disinformation aspect of the tooling, this was done to try and index what services are crawling Pastebin.
- Stage 3: Build PoC From Templates, input the CVE and CanaryID to the specific PoC - I'll explain how the templates work in a second!
Templates? WTF?
Each repository created was built from an initial template with the help of Styx who helped me streamline how I built the template files. Each repo was built from three templates:
- Windows.template.go - Go code created for compilation and usage on windows machines.
- Unix.template.sh - Bash script with curl and echo commands, much more clear than a random binary.
- README.template.md - Template for the readme file to be built on each proof of concept.
The PoC code templates for the go and shell script works by doing the following:
- Creates a call-back URL which is a URL generated via canary.tools that were kindly supplied by Thinkst for a few months access to their API (which works for automation nicely!)
- The windows go binary, gather information about the running environment:
- USERDOMAIN Value - Usually the NetBIOS name of the domain e.g.
zsec.localwould be zsec. - USERDNSDOMAIN Value - the FQDN of the domain; zsec.local
- USERNAME Value - The user running the script at the time
- PATH Variable - Information about the environment variable of the path.
- Target IP - The IP that the binary was being pointed at e.g. CVE-2021-1337.exe -t
10.10.10.1, the IP value would be10.10.10.1. - Hostname - The hostname of the user's system who is running the binary or shell script version.
In later iterations of the PoCs I built sandbox detection is based on IP ranges and Path information to filter out data from sandboxes. I also built a second tool called SandBoxSpy that I leveraged to build out detections for the PoCs within sandbox environments ( I may release this at a later date).
3. Once the information is gathered, takes all of this data and proceeds to build an HTTP request with headers set:
- X-Target-IP - the raw value from the target IP specified in the exe or shell script, both are set within the template either as the first input or input from a flag described in the readme.md.
- Cookie - A Base32 value of the Userdomain, username, path and FQDN combined.
I chose Base32 as it is less common than the typical Base64 used by other outbound communications, also enabled for compression of information being sent outbound.
- X-Hostname - Self-explanatory, sets the hostname from the parameter above.
Theoretically, as an HTTP request is being built, any number of headers can be appended for further data collection. However, the info gathered was minimal to work out sandboxes and potentially identify the PoCs being run on legitimate domains(more on this later in the post).
3. The Linux/shell script takes a canary URL and issues a curl request along with the hostname value on the system where the script has been run as the user agent by selecting the -A flag. This information is collated on the back end along with the execution time and originating IP address.
The Linux side was more limited as I built the shell script to be somewhat transparent in that users running it could at least check what they were running before running it(spoiler alert most did not check anyways!).
Who was it designed for?
AutoPoC was designed with disinformation and data harvesting in mind, the core focus was to gather data on how quick PoCs were pulled from git and what information could be pulled to profile usage.
It was initially designed with poisoning certain feeds as there are known accounts on Twitter and GitHub that trawl both sites for information and auto-run/auto-populate threat intelligence feeds which were apparent when several AutoPoC URLs showed up in various sites. Additional objectives it picked up along the way was profiling sandboxes, TI provides and threat actors alike!
By accident, the project picked up on a lot more information than originally intended including profiling of threat actors, identification of insider threat(s), trickery with *coloured teams and annoying script kiddies!
Where?
It was not angled at a particular group in mind initially and was created for a little bit of fun to see how far it could get, which is initially why it was released on a blatantly obviously fake Github account.
However as GitHub automated investigations flagging is pretty good, this account quickly got marked as suspicious and was later suspended. Next, my interest in what criteria GitHub used for accounts being marked as suspicious was sparked so I began the creation of some falsified accounts and made them look legitimate in an attempt to add to the disinformation criteria.
The accounts used(listed in no particular order) were:
- https://github.com/PwnCast
- https://github.com/JamesCVE - Initial account that had several live PoCs initially
- https://github.com/GoogleProjectZer0
- https://github.com/GoogleProjctZero
- https://github.com/AlAIAL90 - Most active and most recent account
- https://github.com/AKIA27TACKEDYE76PUGU - same account as above but renamed
- https://github.com/AIPOCAI - likewise, but someone flagged it and thus it got removed from GitHub
I am supplying them in case you find them in your logs and suspect adversarial or insider threat/idiocy.
The automation aspect of the framework was built in a manner using GitHub tokens to automatically initialise a git repo then push code to it programmatically.
A task that I was surprised about was not asked more about online, however, upon a few trial and error runs I managed to get that aspect of it working. I may release the harness as to how I did this as a module, I however do not plan on releasing the AutoPoC framework.
An example of the script running with output is shown below:
CVE-2021-23388
5.0
CVE-2020-1920
5.0
CVE-2021-24316
4.3
3/5
[*] Making Directory CVE-2021-23388
[*] Openning and processing Data in /path/to/template/template.poc.sh ...
[*] Closing /path/to/template/template.poc.sh ...
[*] CVE-2021-23388.sh generated!
[*] Openning and processing Data in /path/to/template/template.poc.go ...
[*] Closing /path/to/template/template.poc.go ...
[*] CVE-2021-23388.go generated!
[*] Cross Compile Success!
[*] Openning and processing Data in /path/to/template/template.poc.readme.md ...
[*] Closing /path/to/template/template.poc.readme.md ...
[*] README.md generated!
b'https://pastebin.com/example'
Initialized empty Git repository in /path/to/template/CVE-2021-23388/.git/
[master (root-commit) b7115c3] CVE-2021-23388 Commit
3 files changed, 55 insertions(+)
create mode 100644 CVE-2021-23388.exe
create mode 100644 CVE-2021-23388.sh
create mode 100644 README.md
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 16 threads
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 3.37 MiB | 5.07 MiB/s, done.
Total 5 (delta 0), reused 0 (delta 0)
To https://github.com/example/CVE-2021-23388.git
+ b96f2b3...b7115c3 main -> main (forced update)
The various iterations of the script had detailed logging so I could keep track of what was going where and what account it was posting to.
Timeline?
The original PoCs were released on GitHub in 2020 but the AutoPoC project started in April 2021 and I have halted it in October 2021 spanning it for 6 months total to gather information for research and interest however I may still release the framework.

The screenshot below shows the contributions of the latest GitHub account containing the most active PoC repos.
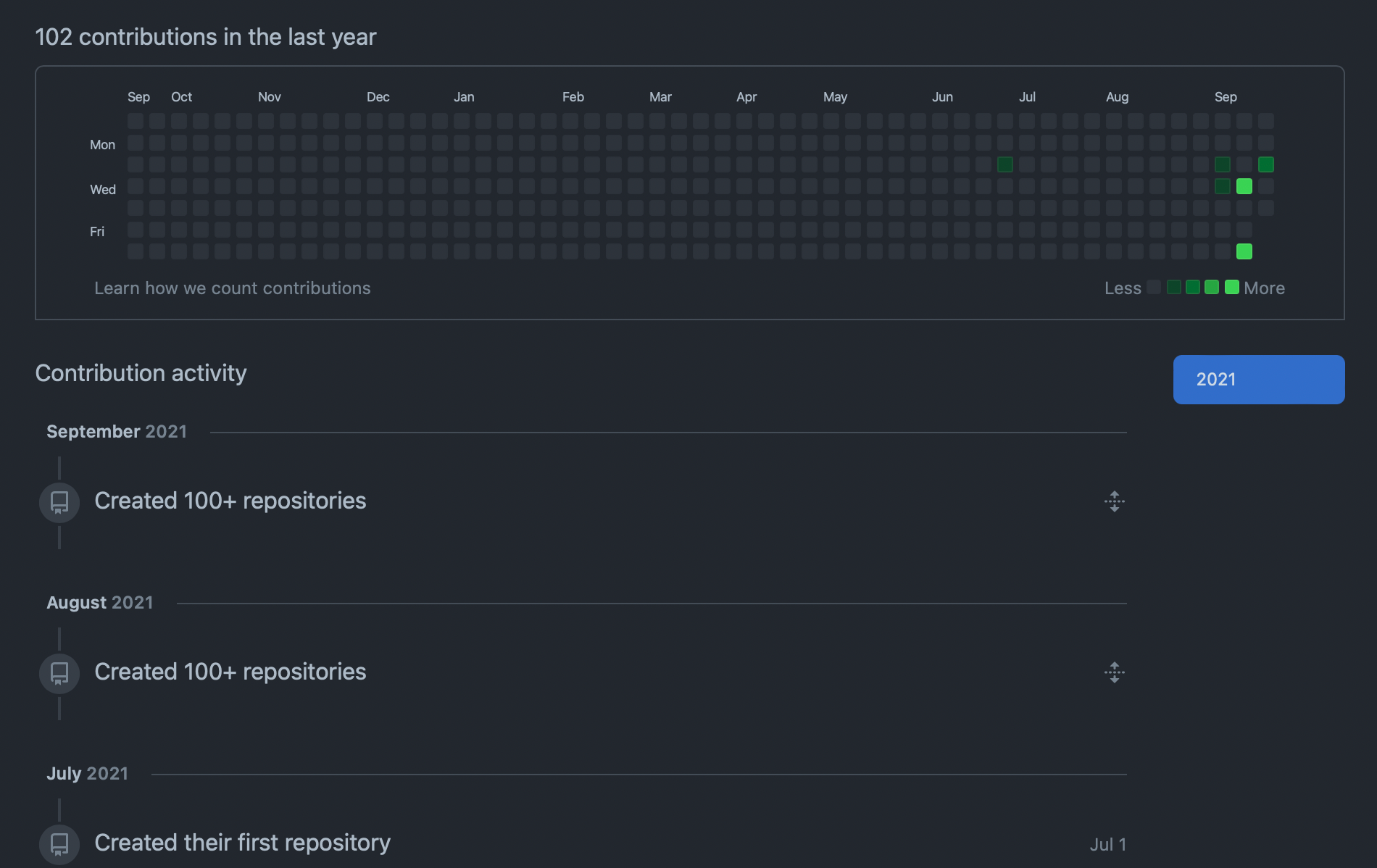
I was going to run it till the end of 2021 however as there is such a large amount of data in such a short space of time I saw it better to kill the project off also the GitHub account got flagged too so I had to pull the data from it and be done with that side.
- SIGRED CVE-2020-1350 (HoneyPoC 1.0) – July 2020
- Exchange CVE-2021-28480 (HoneyPoC 2.0) – April 2021
- Pulse Secure CVE-2021-22893 (HoneyPoC 3.0) – April 2021
- AutoPoC Disinformation Campaign Started – May 2021 -> October 2021
The only PoCs that still remain are the first, second and third but those projects have been archived in read-only mode and clearly marked to not be run, alas I still get hits to this day!
The Data
Now understanding how the tooling works, why it was created and how long the project ran for, it is just as important to process the data harvested and visualise it in an effective manner.
Like the original blog post, I am going to dive into all the tasty tasty data and discuss some of the fallout from data analysis.
GitHub Accounts Sorted by Live PoCs
| GitHub Account Name | Number of PoCs |
|---|---|
| https://github.com/AIPOCAI | 474 |
| https://github.com/PwnCast | 330 |
| https://github.com/AlAIAL90 | 282 |
| https://github.com/JamesCVE | 142 |
| https://github.com/GoogleProjectZer0 | 5 |
| https://github.com/GoogleProjctZero | 1 |
The number of PoCs spread across the various accounts is shown above, there were a few other accounts created but they never had any content. It is also worth noting that the amount of PoC URLs were multiple per PoC sometimes as throughout the iterations I toyed with having different canary URLs per PoC so therefore a PoC could have 2-5 per repo.
Top 10 CVE PoCs
| CVE ID | Number of Executions |
|---|---|
| CVE-2020-36326 | 716 |
| CVE-2021-26084 | 262 |
| CVE-2020-1350 | 218 |
| CVE-2021-22893 | 214 |
| CVE-2021-30551 | 146 |
| CVE-2021-28480 | 134 |
| CVE-2021-28903 | 104 |
| CVE-2021-30540 | 96 |
| CVE-2021-30465 | 94 |
| CVE-2021-29447 | 74 |
The top 10 were mostly affecting Chrome and other products, with only two affecting Windows products, from the data I also noticed a large amount of quick time to execute on VPN products. The Pulse Secure, Cisco and Palo Alto VPN CVEs tended to be picked up really quickly by eastern regions.
AutoPoC Mapped Geographically
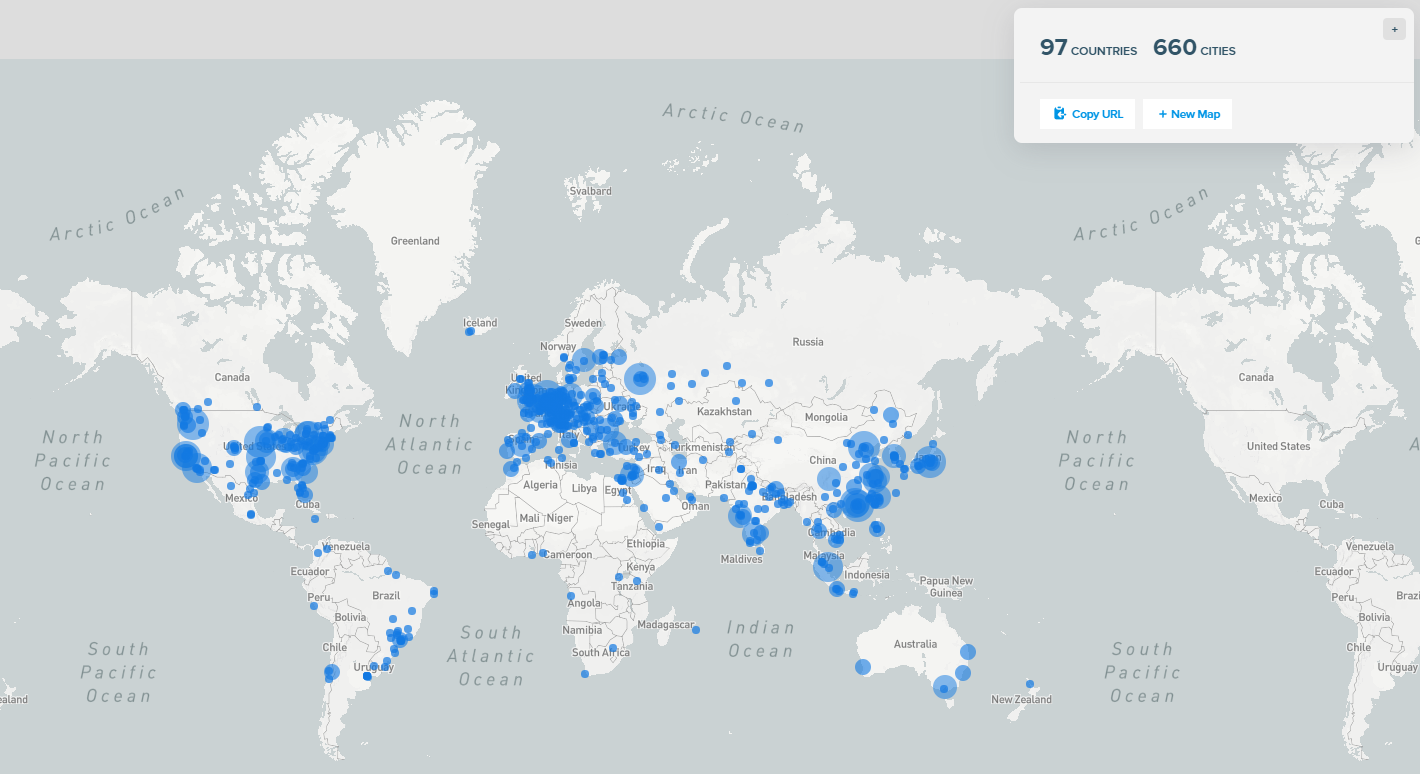
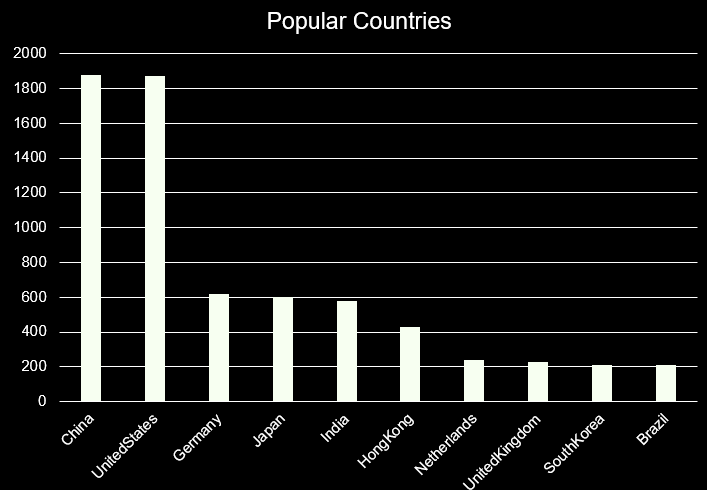
Top 10 Countries sorted by instance amount of executions from source hosts, I have not mapped target IP addresses as there were a lot of domains and the data analysis took a lot of time. I might do a follow up blog post to dive deeper into the data.
| Country Name | Instance Amount |
|---|---|
| China | 1880 |
| UnitedStates | 1870 |
| Germany | 620 |
| Japan | 600 |
| India | 580 |
| HongKong | 430 |
| Netherlands | 240 |
| UnitedKingdom | 230 |
| SouthKorea | 210 |
| Brazil | 210 |
Everyone loves a graph, here's the table above mapped out to show the most popular source countries who executed the various PoCs.
Sandboxes Found
Within the windows binary was path identification, hostname and domain/username identification, this enabled profiling of certain executions and as a result, I found the common hostnames and usernames used by various sandbox services.
It is also what triggered the creation of SandBoxSpy, some of the most used hostnames and usernames of various sandboxes are shown below, if you get a ping from some of these machine names/usernames chances are it is a sandbox rather than a legitimate connection.
- John-PC
- Abby-PC
- Amazing-Avocado
- Walker-PC
- Work
- Ralphs-PC
In addition to hostnames, a large number of IP ranges were detected and added to an ever-growing list of sandboxes for other research I am undertaking for the purposes of operational security safe C2 for red teaming (but that's another project entirely).
- 89.208.29.63/24 - Virus Total Cloud
- 35.187.132.50/24 - VT Cloud but also Google Cloud Platform, a lot of VT uses GCP hosts
Interesting Data

ASN and IP Block List
| ASN ID | Number | Info |
|---|---|---|
| AS9808 | 380 | China Mobile Communications Group Co., Ltd. |
| AS4134 | 340 | CHINANET-BACKBONE |
| AS14061 | 290 | DigitalOcean, LLC |
| AS4808 | 250 | China Unicom Beijing Province Network |
| AS15169 | 240 | Google LLC |
| AS36351 | 230 | SoftLayer Technologies Inc |
| AS13335 | 200 | Cloudflare, Inc. |
| AS16509 | 190 | Amazon.com, Inc. |
| AS19084 | 180 | ColoUp |
| AS208294 | 180 | CIA TRIAD SECURITY LLC |
| AS4837 | 150 | CHINA UNICOM China169 Backbone |
| AS36352 | 140 | ColoCrossing |
| AS9009 | 140 | M247 Ltd |
| AS205100 | 120 | F3 Netze e.V. |
| AS3462 | 110 | Data Communication Business Group |
| AS24560 | 100 | Bharti Airtel Ltd., Telemedia Services |
| AS4847 | 90 | China Networks Inter-Exchange |
| AS4812 | 80 | China Telecom (Group) |
| AS63949 | 80 | Linode, LLC |
| AS174 | 70 | Cogent Communications |
IP Data Overall from all the Source IP addresses:
Graphs of Information
In terms of execution of the Windows binaries, the graph below breaks down the different split based on source IP, information from execution hosts such as hostname and FQDN of domains.
Unique User agents
There were a lot of user agents in addition to the various PoCs that set the hostname as the user agent, a selection of some of the interesting and unique ones are shown below. A lot of sandboxes and abnormalities were identified based on different strings.
| User Agent | Description |
|---|---|
| Mozilla/5.0 (Windows NT 3.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36 | Suspected sandbox, based on Windows 3.1 running Chrome 37! |
| Mozilla/5.0 (X11; U; Linux i686; ko-KP, en; rv:1.8.1.8) Gecko/20090718 《붉은별》/2.5 NaenaraBrowser/2.0.0.8 | Appears to be Red Star OS from North Korea and the source IP also matched up to a similar region |
| Mozilla/5.0 (X11; U; Linux i686; ko-KP; rv: 19.1br) Gecko/20130508 Fedora/1.9.1-2.5.rs3.0 NaenaraBrowser/3.5b4 | Similar to above |
| Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0 (not really), | Spoofed user agent |
| Mozilla/5.0 (Windows NT 12.0; Arm64; x64; rv:99.0) Gecko/20210505 Firefox/99.0 (not really), | Spoofed user agent, Apparently windows 12? |
| Mozilla/5.0 (X11; CrOS aarch64 13099.85.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.110 Safari/537.36 | |
| Mozilla/5.0 (X11; CrOS i686 4319.74.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.57 Safari/537.36 | |
| Mozilla/5.0 (X11; CrOS x86_64 13816.55.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.86 Safari/537.36, | |
| Mozilla/5.0 (X11; Fedora; Linux x86_64; rv:88.0) Gecko/20100101 Firefox/88.0 | |
| Mozilla/5.0 (X11; Fedora; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0 | |
| Mozilla/5.0 (X11; Linux aarch64; rv:78.0) Gecko/20100101 Firefox/78.0 | |
| Mozilla/5.0 (X11; Linux i586; rv:90.0) Gecko/20100101 Firefox/90.0 | |
| Mozilla/5.0 (X11; Linux i686 on x86_64; rv:47.0) Gecko/20100101 Firefox/47.0 | |
| Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.84 Safari/537.36 | |
| Mozilla/5.0 (X11; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 | |
| Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/534.34 (KHTML, like Gecko) AguseScan Safari/534.34 | |
| Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Goanna/4.8 Firefox/68.0 PaleMoon/29.1.1 | Windows with random browser |
Machine Hostnames
There were a lot of hostnames disclosed that gave away what company or what user was using the HoneyPoC, I was able to map out a lot of companies based on the hostname alone and data on GitHub, I used this to get in touch with said companies and notify them of what I had found.
Targeted IPs & Domains
Within the Windows binaries, there was a header set, the output below shows a sample of the IPs targetted by the various PoCS, essentially what attackers were targeting and where they were located. There was a total of 42 internal IP addresses in the list and 10-15 internal domains listed.
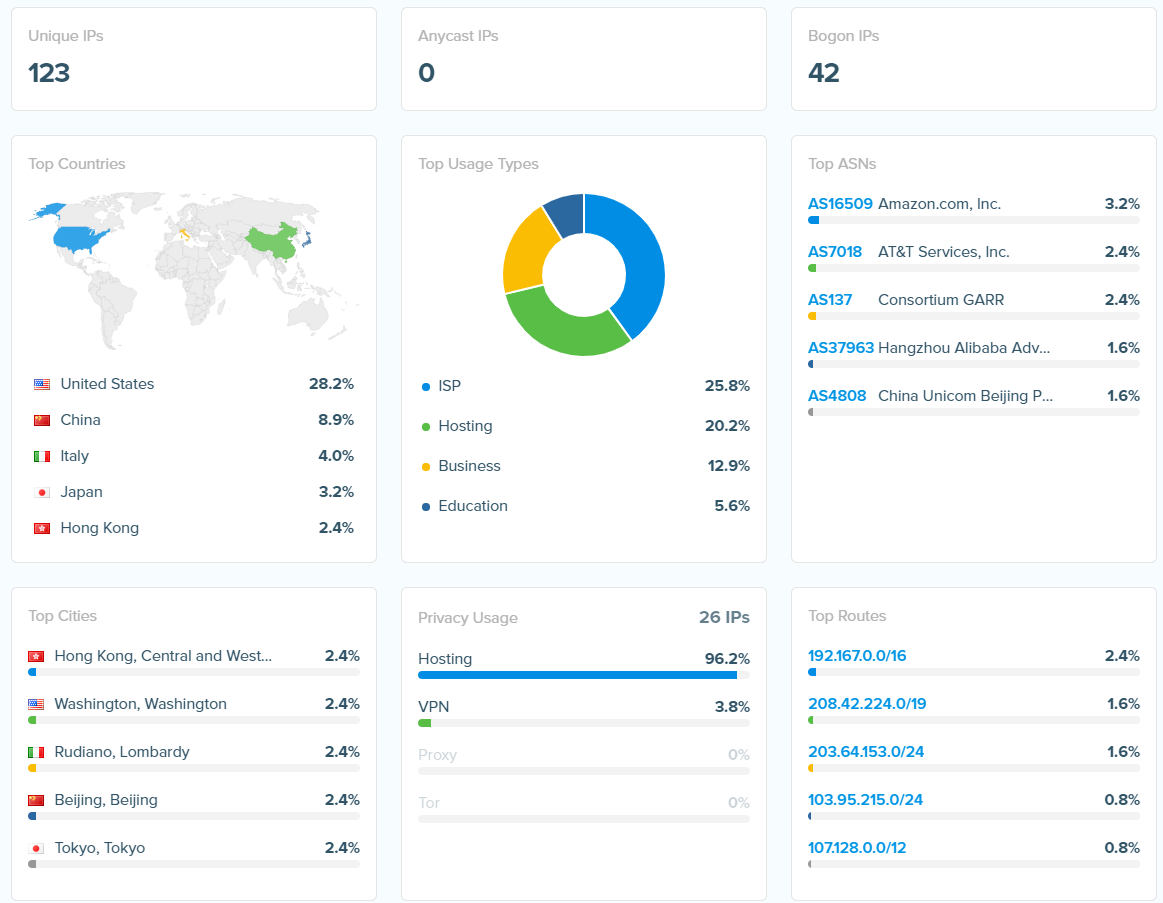
The target IP info was stripped by what appeared to be a lot of proxies however the Cookie data that was used within the template was not therefore it was possible to B32 decode the cookies and retrieve the path information along with hostnames and usernames.
The Feeds
HoneyPoC and AutoPoC repositories and files made it into a lot of feeds, lots of vendors who clearly crawl things without doing additional validation. The AutoPoC data ended up in a lot of Git trawl repos:
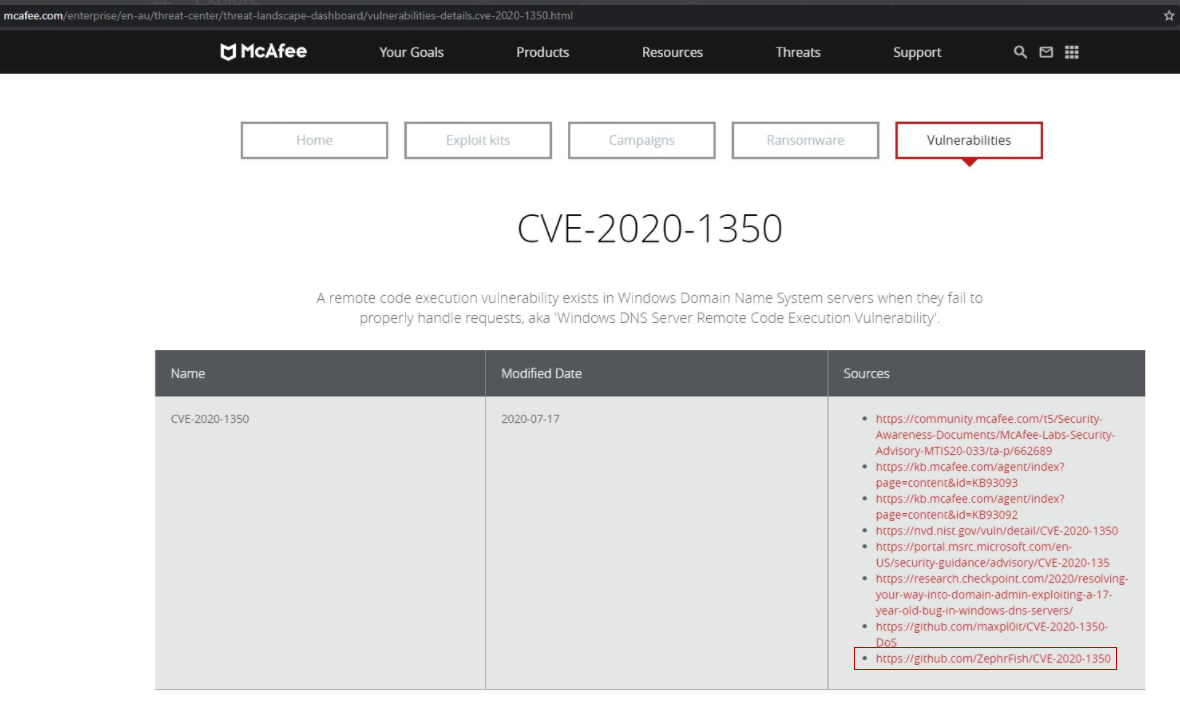
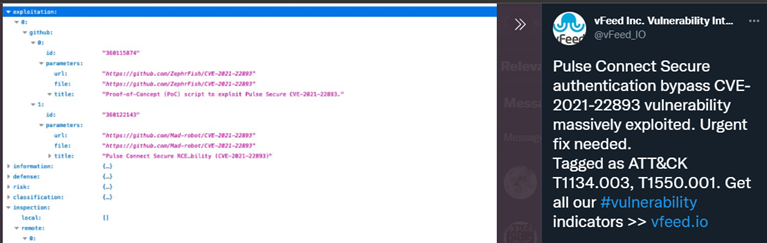

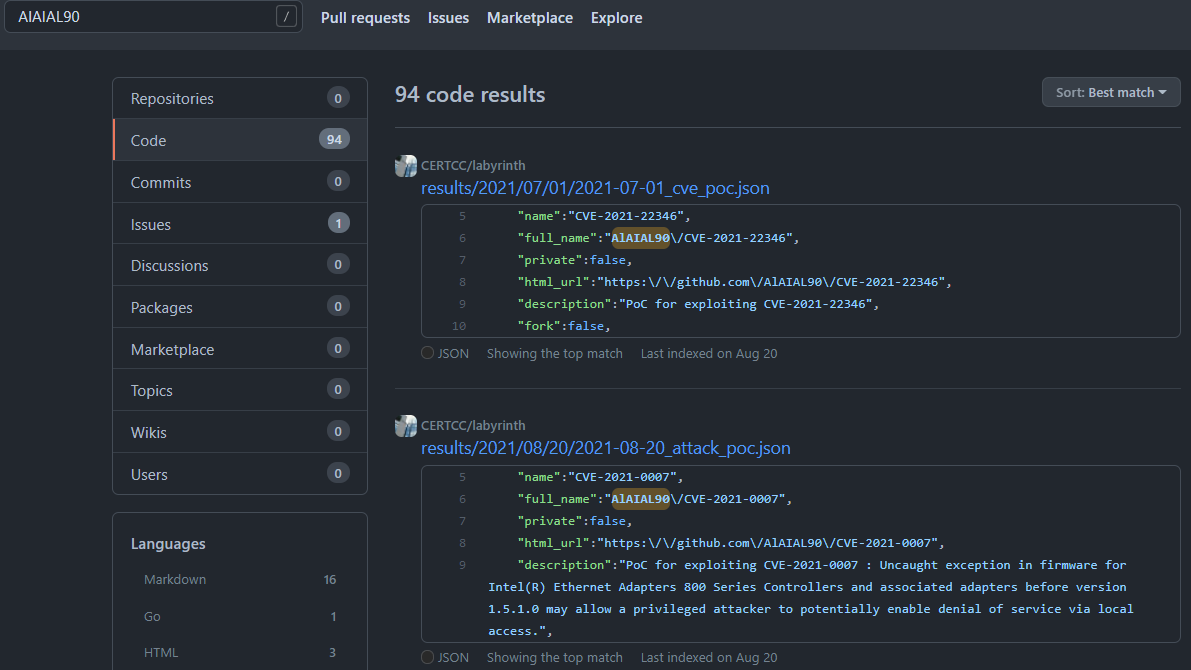
This was an interesting issue that was opened, and is one of the reasons I wrote into the framework to change git accounts:
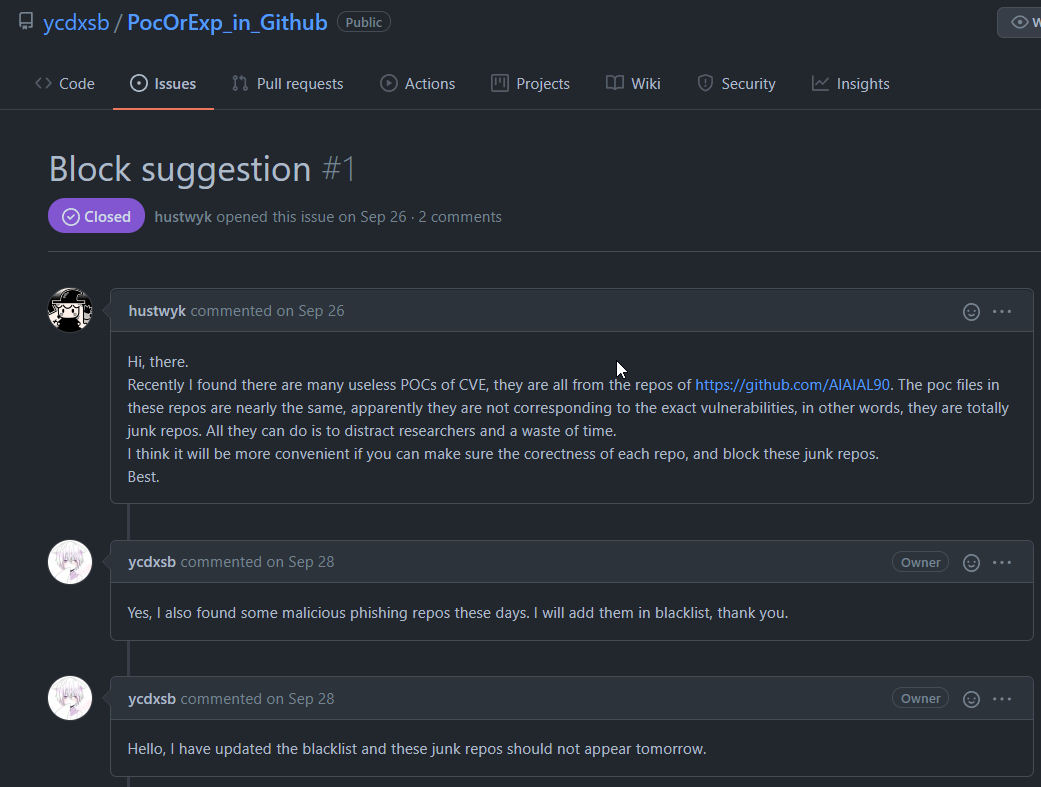
I have not included a few screenshots shared with me regarding internal feeds upon request by folks that sent them in. There were quite a few folks who got in touch over the last 18 months with screencaps and things of feeds, SIEMs, internal chats and various other data.
The original PoCs got their own signature within VirusTotal by a lot of vendors (bad joke), stay tuned that'll be my next 0-Day ;).
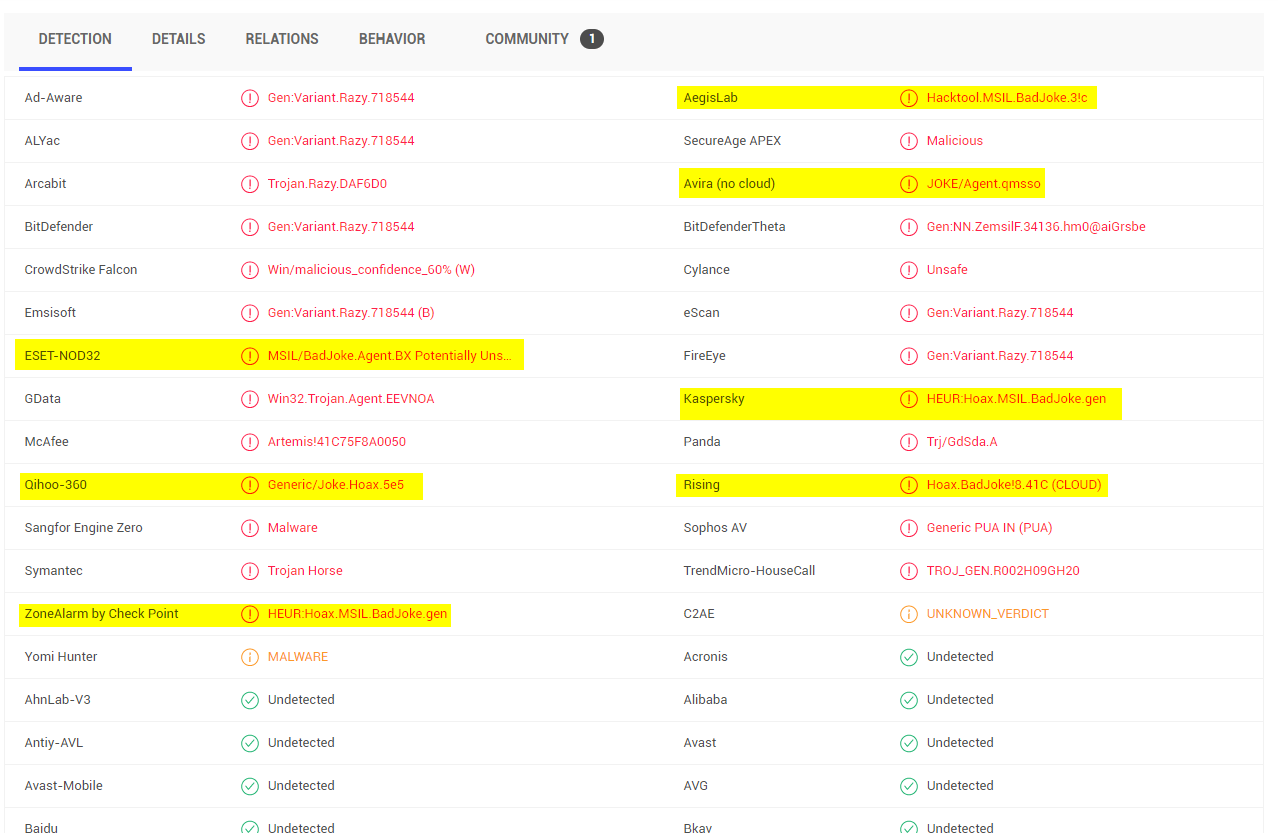
Not a feed, but interesting to see that the GitHub trust and safety team looked into one of the accounts and found nothing wrong with it, a bit strange but also seems to be a lack of validation.
Findings
Upon looking into all of the data and all of the output from the different CVEs, I found a few what looked like interesting domains including a few companies. There was also a significant amount of blind sharing amongst TI and teams both red and blue within companies, blindly sharing and executing PoCs.

Of the insider threats and internal information the following industries were found to execute the PoCs and a few internal executions were found:
- Industrial Control Systems Companies
- Apparent Espionage from Foreign Intelligence Services
- Multiple Government Depts identified based on IP range and hosts being targeted.
- A Video Games Company
- Some Airlines
- A lot of 'security companies
- Several Financial Companies (including two banks)
In addition to finding data myself, I was also sent a bunch of messages from followers of the project indicating that the PoC had been found and was being watched by interested parties.

The Upset
Some people got upset during this project and as a result, there was a large variety of GitHub issues, tweets, and angry comments from folks. As one can imagine the AutoPoC project designed to push out repos autonomously was picked up by a lot of researchers who index Github and thus a few got a little upset.

When I released the original post and PoC some of my friends were a little raging at me:

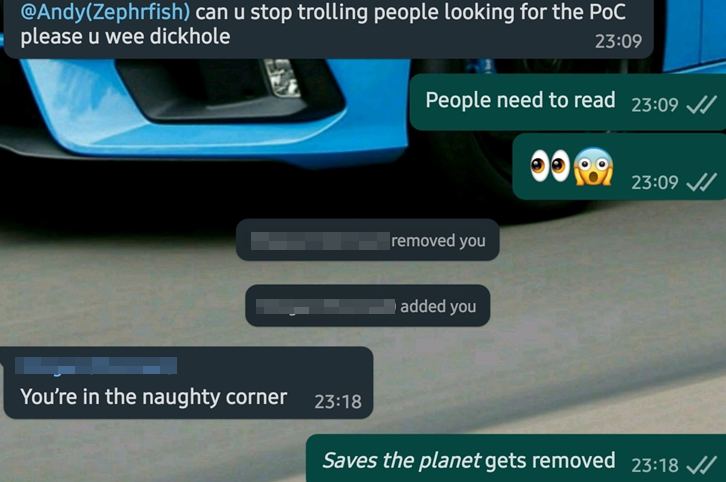

Tweets and DMs:
The most recent fallout was when someone got a little raging and put out a tweet complaining then flagged the account to Git, but alas at this point I had the data needed :-).
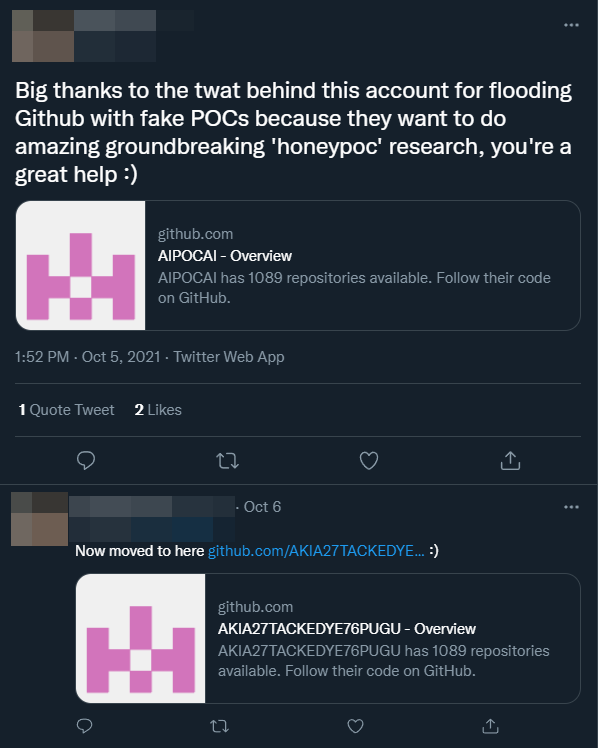
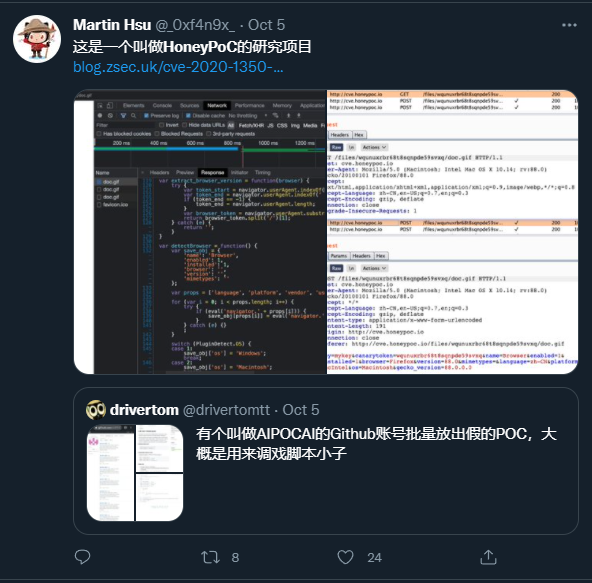
One of the things I did notice while doing data analysis was the sheer amount of interest from Chinese Twitter accounts.
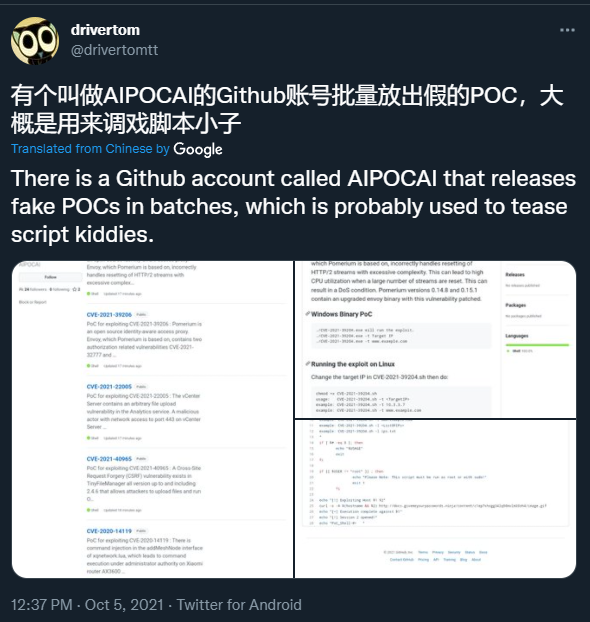
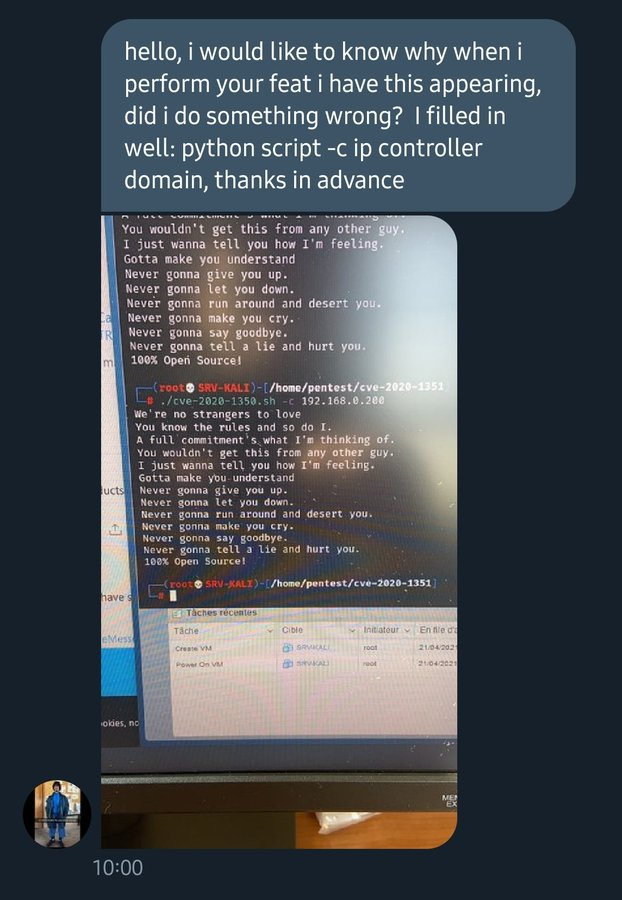
Lack of understanding rang true quite a few times from opportunistic hackers and script kiddies:
There were a lot of tickets opened on the various PoCs on GitHub under different accounts complaining and the likes.

There were also issues opened in Chinese:
Google translate tried, if there are any native speakers who fancy a better translation ping me!
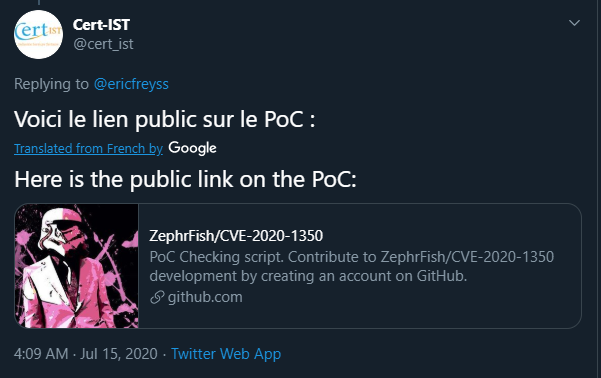
A few CERTs got involved and tweeted out the original HoneyPoC without checking it:
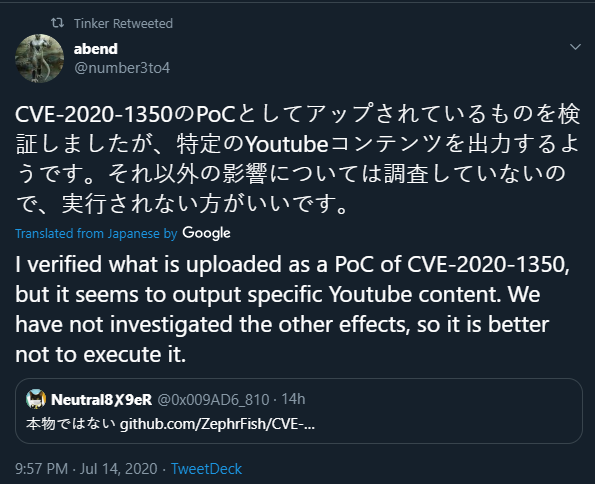
Detecting HoneyPoC Usage and Creation
This project was around how far spread can disinformation go and which automated threat intel feeds would pick up the CVEs and run with them. There was no focus on how to detect usage and while the results of the project have found a lot of interesting information from the runtime, profiling sandboxes and trends in vulnerabilities and where they're leveraged.
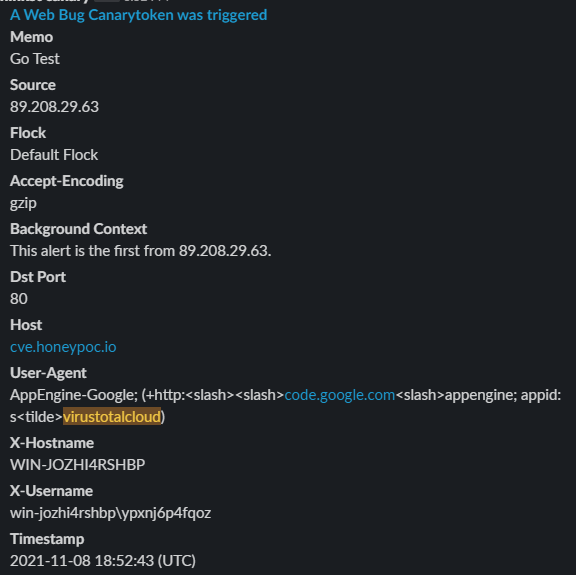
It is equally important that should my automated code or similar make it out into the wild that I release some detections for it. So the first IoC usually will be the call-back domain and the signature of what a request will look like.
- Domain:
cve.honeypoc.ioordocs.givemeyourpasswords.ninja - Github(s):
- https://github.com/PwnCast
- https://github.com/JamesCVE
- https://github.com/GoogleProjectZer0
- https://github.com/GoogleProjctZero
- https://github.com/AlAIAL90
- https://github.com/AKIA27TACKEDYE76PUGU
- https://github.com/AIPOCAI
- Pastebin Example: https://pastebin.com/Bz10AmGD
New PoC Published for CVE-2021-30783 located at https://github.com/AlAIAL90/CVE-2021-30783.git - Sample Request:
Yara Rule (Thanks to my Colleague Anton for the help with this one)
I'm not a blue teamer or detection engineer by trade, however, the Yara rules before are my attempt at some detection for the domains and binaries being executed historically within your environment.
rule HoneyPoC_URLDetect {
meta:
description = "HoneyPoC AutoPoC URL detection"
author = "Andy Gill"
reference = "blog.zsec.uk/honeypoc-ultimate/"
date = "2021/11/13"
hash = "b6807027ac171252cf47eb28454c044644352c9f2fabd65d3f23075a0e395768"
strings:
$a = "honeypoc.io" nocase
$b = "canarytokens.com" nocase
$c = "givemeyourpasswords.ninja" nocase
condition:
$a or $b or $c
}The following yara rule can be used with something like PasteHunter to search for specific strings in Pastebin links.
rule HoneyPoC_Pastebin
{
meta:
description = "HoneyPoC AutoPoC Pastebin detection"
author = "Andy Gill"
reference = "blog.zsec.uk/honeypoc-ultimate/"
date = "2021/11/13"
strings:
$a = "New PoC Published for" nocase wide ascii fullword
condition:
$a
}
Conclusion and Thanks
Thank you for reading this post and if you saw me present it at BSides London the talk link will be added to this blog and updated, thanks for listening! The lessons learned here are a few from both sides, the underlying one being that folks will run random binaries from the internet without checking what they do and that's just a fact sadly. Other lessons I have learned have been in social engineering passively, making a legitimate-looking repository is enough to convince most script kiddies or threat intel crawlers that the repo is real.
Some people got upset that their indexing of GitHub was spoiled by HoneyPoC and as a result, a few of the accounts spun up over the duration of the project got suspended:
The chaos that HoneyPoC and AutoPoC created and the interesting data that erupted from both projects wouldn't be possible without the help of a few folks be it helping with the development of my shitty PoC code or facilitating data analytics. I'd like to thank the following folks for their contributions to the AutoPoC project:
- Styx - Took my code that worked and made it much more modular and extensible plus offered a lot of input on things to add and try.
- Aidan - He taught me a lot about templating and spent a few nights explaining how to take the chaos one further. Also helped build the template structure for AutoPoC v0.01, it went through many iterations before what it is today.
- Thinkst Canary - Supplied a great free service via CanaryTokens.org but when they heard about my automated API idea, gave me access to their premium console which was a large amount of input to the way AutoPoC is structured.
- Kevin Beaumont - Well there are a few things to thank Kevin for but the first is the initial idea that sparked me to design and build AutoPoC. Not only did he suggest it but followed up by sending some initial funding for VPS and other hosting thus honeypoc.io was born with some services hanging off it.
- TinkerSec - Tinker and I put out the original HoneyPoC on our GitHub pages and with our presence in the industry drove a little legitimacy to the projects. He has also offered a lot of feedback and input on my other ideas and is a genuinely nice person whom you should follow on Twitter!
- IPInfo.io - Provided access to their summarize IPs tooling for free (which is now free anyway) to do a bit of deeper analysis into the IPs and data found.
Finally, feel free to scan the following QR code for more information on the project:

